Have you ever wondered how your phone recognizes faces in photos or how a self-driving car detects road signs, lanes, and pedestrians? These tasks are often powered by convolutional neural networks, also called CNNs.
CNNs are a special type of deep learning model designed to work especially well with images. They help computers identify patterns such as edges, shapes, textures, objects, and faces. Without CNNs and similar visual AI methods, many modern image recognition tools would be much less accurate.
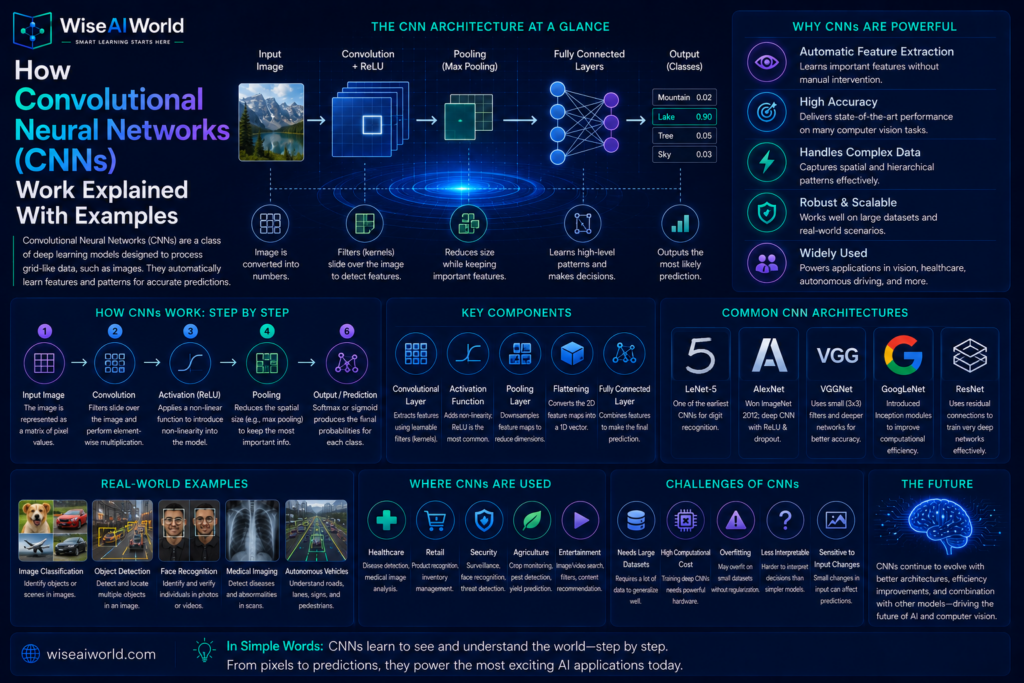
For beginners, CNNs may sound complicated at first. But the main idea is simple: a CNN looks at an image piece by piece, finds useful patterns, and combines those patterns to understand what the image contains.
What Is a Convolutional Neural Network?
A convolutional neural network is a type of artificial neural network commonly used for image-related tasks.
It is called “convolutional” because it uses a process called convolution. In simple terms, convolution means scanning small parts of an image with tiny pattern detectors called filters.
A CNN does not look at an image the same way humans do. It sees an image as numbers. Every pixel has values that represent color and brightness. The CNN processes these numbers through layers to find patterns.
CNNs are widely used for:
- Image classification
- Face recognition
- Object detection
- Medical image analysis
- Self-driving car vision
- Security camera analysis
- Handwriting recognition
- Product defect detection
For example, if a CNN is trained to recognize dogs, it may first learn simple visual patterns like edges and curves. Later layers may learn fur texture, eyes, ears, legs, and full dog shapes.
CNNs are an important part of deep learning. If you are new to deep learning, read What Is Deep Learning and How Is It Different From Machine Learning first.
Why CNNs Are Useful for Images
Images contain spatial information. This means the location of pixels matters.
For example, a face has eyes above the nose and a mouth below the nose. A road sign has a shape, border, symbol, and color arranged in a meaningful way.
Traditional machine learning models often struggle with raw images because images contain many pixels. A simple image may have thousands or millions of pixel values.
CNNs are useful because they can learn local visual patterns.
Instead of analyzing every pixel separately, CNNs scan small regions of the image. This helps them detect patterns no matter where they appear.
For example, a CNN can learn what an eye looks like and detect it in different parts of a face image. It can learn what a wheel looks like and find it on cars, bicycles, or trucks.
This makes CNNs powerful for visual tasks.
A practical example is photo organization. When a photo app groups pictures of the same person, a CNN-like model may help detect facial patterns across many images.
How Images Become Numbers
Before a CNN can analyze an image, the image must be converted into numbers.
A digital image is made of pixels. Each pixel contains color information.
A black-and-white image may have one number per pixel, representing brightness. A color image usually has three values per pixel: red, green, and blue.
For example, a small color image may be represented as a grid of numbers like this:
- Red channel values
- Green channel values
- Blue channel values
The CNN does not see a “cat” or a “car” directly. It sees pixel values. Through training, it learns which pixel patterns are connected to objects.
For example, if the model sees many cat images, it may learn that certain combinations of pixels represent whiskers, ears, eyes, fur, and body shape.
This is why training data matters. A CNN needs many examples to learn visual patterns accurately.
If a model is trained mostly on clear daylight images, it may struggle with blurry, dark, or unusual images.
What Are Filters in CNNs?
Filters are one of the most important ideas in convolutional neural networks.
A filter is a small grid of numbers that slides across an image to detect a specific pattern.
Think of a filter as a tiny pattern detector.
Different filters can detect different visual features, such as:
- Horizontal edges
- Vertical edges
- Curves
- Corners
- Textures
- Color changes
- Simple shapes
For example, one filter may become good at detecting edges. Another may detect circular shapes. Another may detect rough textures.
As the filter moves across the image, it produces a feature map. A feature map shows where that pattern appears in the image.
A simple real-world example is road sign detection. One filter may detect the edge of a sign. Another may detect the shape. Another may detect color patterns. Later layers combine this information to recognize the sign.
Early CNN layers usually detect simple patterns. Deeper layers detect more complex patterns.
What Is Convolution?
Convolution is the process of applying filters to an image.
The filter moves across the image step by step. At each position, it compares itself with the pixel values in that small area. If the pattern matches strongly, the output value becomes high. If it does not match, the output is lower.
This creates a new grid called a feature map.
In simple words:
- The image goes in.
- A filter scans the image.
- The filter detects a pattern.
- The result becomes a feature map.
For example, imagine a CNN analyzing a handwritten number. A filter may detect curved strokes. Another filter may detect straight lines. When these feature maps are combined, the CNN can identify whether the digit is 3, 5, 8, or 9.
Convolution helps the model focus on meaningful visual patterns instead of treating every pixel separately.
It also helps reduce complexity because the same filter can be used across the whole image.
What Is Pooling in CNNs?
Pooling is another important step in many CNNs.
Pooling reduces the size of feature maps while keeping the most important information. This helps the model become faster and less sensitive to small changes in image position.
The most common type is max pooling.
Max pooling takes a small area of the feature map and keeps only the highest value. This means it keeps the strongest detected pattern in that area.
For example, if a filter detects an edge anywhere inside a small region, max pooling keeps that strong signal.
Pooling is useful because an object may appear slightly shifted in an image. A cat may be a little to the left or right. A face may be slightly higher or lower. Pooling helps the CNN recognize patterns even when they are not perfectly aligned.
A real-world example is face recognition. A person’s face may appear at different angles or positions. Pooling helps the model focus on important features instead of exact pixel locations.
Layers in a Convolutional Neural Network
A CNN usually has several types of layers working together.
Convolutional Layers
These layers apply filters to detect features.
Early convolutional layers may detect edges and colors. Middle layers may detect textures and shapes. Deeper layers may detect object parts or full objects.
Activation Layers
Activation functions help the network learn complex patterns.
A common activation function is ReLU. It keeps positive values and removes negative values. This helps the model focus on useful signals.
Pooling Layers
Pooling layers reduce feature map size and keep important patterns.
This makes the model more efficient and helps it handle small changes in image position.
Fully Connected Layers
Near the end of the network, fully connected layers use the detected features to make a final decision.
For example, after detecting ears, eyes, fur, and shape, the model may predict whether the image is a cat or dog.
Output Layer
The output layer gives the final result.
For image classification, it may produce probabilities such as:
- Cat: 92%
- Dog: 6%
- Rabbit: 2%
The highest probability is usually the model’s prediction.
Example: How a CNN Recognizes a Cat
Let’s walk through a simple example.
Imagine a CNN trained to recognize cats.
First, the image is converted into pixel values.
Second, early filters scan the image and detect simple patterns such as edges, curves, and color changes.
Third, middle layers combine simple patterns into more meaningful features such as eyes, ears, whiskers, and fur texture.
Fourth, deeper layers combine those features into larger patterns that look like a cat’s face or body.
Fifth, the final layers calculate the probability that the image belongs to different categories.
The output may look like:
| Class | Probability |
|---|---|
| Cat | 95% |
| Dog | 3% |
| Fox | 2% |
The model predicts “cat” because the visual patterns strongly match what it learned from cat images.
This process is not human understanding. The CNN does not know what a cat is in the way a person does. It recognizes learned visual patterns.
Real-World Uses of CNNs
CNNs are used in many practical applications.
Face Recognition
CNNs help detect and compare facial features. They are used in phone unlock systems, photo apps, and security tools.
Medical Imaging
CNNs can help analyze X-rays, MRI scans, CT scans, and skin images. They may assist doctors by highlighting patterns that need review.
These tools should support medical professionals, not replace them.
Self-Driving Cars
Autonomous vehicle systems use CNNs and other computer vision models to detect lanes, signs, pedestrians, vehicles, and road conditions.
Manufacturing Quality Control
Factories use CNNs to detect product defects such as scratches, cracks, missing parts, or shape problems.
Agriculture
CNNs can help identify crop diseases, monitor plant growth, and detect pests using drone or field images.
Retail and E-Commerce
Shopping platforms can use CNNs for visual search. A user may upload a photo of a product, and the system finds similar items.
These examples show why CNNs are so important in visual AI.
Limitations of CNNs
CNNs are powerful, but they are not perfect.
They need large amounts of labeled image data. If the training data is poor, the model may perform poorly.
CNNs can also be affected by:
- Blurry images
- Poor lighting
- Unusual angles
- Biased datasets
- Small training samples
- Background distractions
- Objects partly hidden from view
For example, a CNN trained mostly on daytime road images may struggle at night or during heavy rain.
CNNs can also make confident mistakes. A model may classify an image incorrectly if it detects misleading patterns.
This is why CNNs should be tested carefully before being used in important areas like healthcare, safety, or finance.
Human review is still necessary for high-risk decisions.
Key Takeaways
- A convolutional neural network is a deep learning model commonly used for image tasks.
- CNNs process images as grids of pixel values.
- Filters scan images to detect patterns such as edges, textures, shapes, and objects.
- Convolution creates feature maps that show where patterns appear.
- Pooling reduces feature map size while keeping important information.
- CNNs are used in face recognition, medical imaging, self-driving cars, agriculture, manufacturing, and visual search.
Conclusion
Convolutional neural networks help computers understand images by scanning them for useful visual patterns. Instead of seeing a photo the way humans do, a CNN processes pixel values through filters, layers, feature maps, and final predictions.
The basic idea is easier than it sounds: early layers detect simple patterns, deeper layers combine them into complex features, and the final layers make a prediction. This makes CNNs especially useful for image recognition, face detection, medical scans, and many computer vision tasks.
Next, you can learn about recurrent neural networks and how they handle sequence data like text, speech, and time-based information. Which CNN example interests you most: face recognition, medical imaging, self-driving cars, or product defect detection?
Manish Prakash Dubey is an AI educator and technology writer based in India. He founded WiseAIWorld to make artificial intelligence simple and practical for students, professionals, and beginners. His work focuses on AI basics, machine learning, deep learning, NLP, computer vision, and real-world AI tools.