Imagine you study for an exam by memorizing every question and answer from last year’s paper word for word. On exam day, if the questions are identical, you will score perfectly. But if even a few questions are different, you will struggle badly because you memorized specific answers rather than understanding the underlying concepts.
That is exactly what overfitting is in machine learning. A model that has overfit its training data has memorized specific examples rather than learning the underlying patterns. It performs brilliantly on data it has seen before and fails on data it has never encountered. This is one of the most common and important problems in all of machine learning, and understanding it is essential for anyone working with or learning about AI.
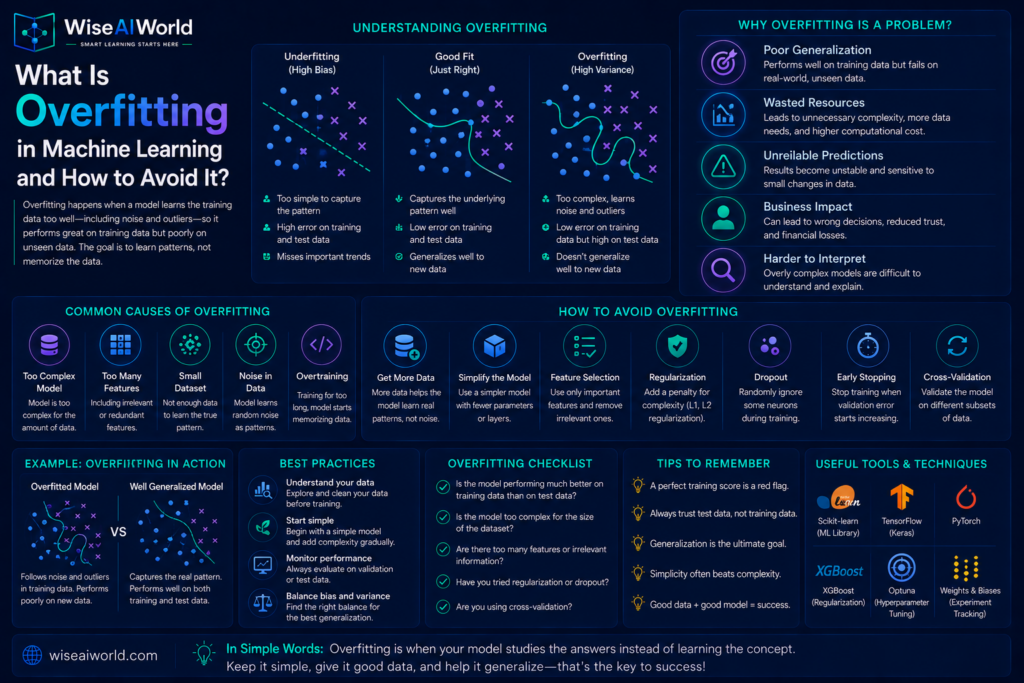
What Is Overfitting?
Overfitting occurs when a model learns the training data too well, capturing not just the genuine underlying patterns but also the noise, random fluctuations, and irrelevant details specific to the training examples. According to Lenovo’s machine learning guide, an overfit model performs excellently on training data but generalizes poorly to new, unseen data, which is the only data that actually matters in a real-world deployment.
In technical terms, an overfit model has low bias but high variance. Low bias means it fits the training data closely. High variance means its predictions change dramatically when applied to slightly different data. This combination is what makes overfitting so damaging to real-world performance.
According to research cited by MindInventory, approximately 85 percent of machine learning projects fail, and poor data quality combined with problems like overfitting are among the leading causes. Getting this balance right is therefore not just an academic concern. It directly determines whether an AI system delivers real-world value or not.
A Simple Example of Overfitting
Suppose you are building a model to predict whether a loan applicant will repay their debt. You train the model on 500 historical customer records. The model achieves 99 percent accuracy on those 500 training records, which sounds impressive.
But when you test the model on 100 new applicants it has never seen, accuracy drops to 62 percent. The model has memorized the specific details of those 500 training cases rather than learning the broader patterns that indicate creditworthiness. It has overfit.
A good model would show similar accuracy on both training data and new data. A large gap between training performance and test performance is the clearest signal of overfitting.
What Causes Overfitting?
Understanding the causes of overfitting helps you prevent it before it happens. According to Google’s Machine Learning Crash Course, overfitting is broadly caused by two problems: the training data does not adequately represent real-world data, or the model is too complex for the amount of data available.
Too Little Training Data
When a dataset is small, a complex model can memorize it entirely. With only a few hundred examples, a deep neural network with millions of parameters has enough capacity to remember every training case rather than learn general patterns. The model essentially treats each training example as a rule rather than a data point.
Model Too Complex for the Task
A model that is far more complex than the problem requires will find patterns in noise. A deep neural network with many layers applied to a simple classification problem with limited data will pick up on irrelevant quirks in the training set that do not generalize to the real world.
Training for Too Long
Training a model for too many passes through the training data, called epochs, can cause overfitting. In early training, the model learns genuine patterns. As training continues past a certain point, it begins memorizing noise and specific details. Performance on training data keeps improving while performance on new data starts to decline.
Noisy or Low-Quality Data
If training data contains errors, mislabeled examples, or irrelevant features, a model may learn those mistakes as if they were genuine patterns. The model then faithfully reproduces those errors when making predictions on new data.
Too Many Features Relative to Data Points
When a model has many input features but relatively few training examples, it can find spurious correlations between features and outcomes that appear meaningful in the training data but are actually random coincidences. This is sometimes called the curse of dimensionality.
How to Detect Overfitting
The most reliable way to detect overfitting is to compare model performance on training data versus held-out test data. According to Aya Data’s complete guide, the key warning signs are high accuracy on training data paired with significantly lower accuracy on test data, and a training loss curve that keeps decreasing while the validation loss curve stops decreasing or starts increasing.
In practice, machine learning practitioners always split their data into at least two sets before training. The training set is used to train the model. The test set is kept separate and used only to evaluate final performance. A well-generalizing model will show similar performance on both. A poorly generalizing, overfit model will show a large gap.
Many practitioners use a three-way split: training set, validation set, and test set. The validation set is used during training to monitor performance on unseen data and catch overfitting early. The test set is reserved for final evaluation only. This approach connects directly to how AI actually works, which you can read about in our guide on .
How to Prevent and Fix Overfitting
The good news is that overfitting is well understood and there are multiple proven techniques to prevent or reduce it. The right choice depends on the specific situation.
Get More Training Data
The most direct solution to overfitting is more data. With a larger and more diverse training set, it becomes much harder for a model to memorize specific examples because there are simply too many of them. The model is forced to learn genuine patterns instead. This is not always possible due to data availability or collection costs, but when it is an option it is usually the most effective remedy.
Use a Simpler Model
If the model is more complex than the problem requires, reducing its complexity often reduces overfitting. For a classification task with a small structured dataset, a decision tree or logistic regression model may generalize far better than a deep neural network. Matching model complexity to problem complexity is a fundamental principle of good machine learning practice.
Regularization
Regularization is a family of techniques that add a penalty to the model during training for being overly complex. The two most common are L1 regularization, which can reduce some model parameters to zero effectively removing them, and L2 regularization, which penalises large parameter values and encourages the model to spread importance more evenly across features. Both approaches push the model toward simpler solutions that generalize better. According to Number Analytics, regularization is one of the most widely used and reliable techniques for preventing overfitting in practice.
Dropout
Dropout is a regularization technique specific to neural networks. During training, a random percentage of neurons, typically 20 to 50 percent, are temporarily switched off on each pass through the data. This prevents the network from becoming too dependent on any specific neurons or pathways and forces it to learn more robust, distributed representations. Dropout is one of the most effective tools for reducing overfitting in models.
Early Stopping
Early stopping monitors model performance on a validation set during training and stops training when validation performance stops improving, even if training performance is still getting better. This prevents the model from continuing to memorize training data after it has already learned all the genuinely useful patterns. It is simple, computationally cheap, and highly effective.
Cross-Validation
Cross-validation is a technique where the training data is divided into multiple subsets called folds. The model is trained multiple times, each time using a different fold as the validation set and the remaining folds for training. Performance is averaged across all folds to get a more reliable estimate of how well the model will generalize. The most common variant is k-fold cross-validation, where k is typically 5 or 10.
Data Augmentation
Data augmentation artificially increases the size and diversity of a training dataset by creating modified versions of existing examples. For image recognition tasks, this might involve rotating, flipping, cropping, or adjusting the brightness of training images. For text tasks, it might involve paraphrasing or synonym replacement. The augmented examples help the model learn patterns that generalize rather than memorizing specific images or texts. According to Number Analytics, data augmentation is particularly effective in image recognition scenarios where collecting genuinely new labeled images is expensive.
Feature Selection
Reducing the number of input features to only the most relevant ones can significantly reduce overfitting, particularly when the dataset is small relative to the number of available features. Techniques like recursive feature elimination, principal component analysis, and domain knowledge-based selection help identify which features genuinely predict the outcome and which are noise.
Overfitting vs Underfitting
Overfitting has an opposite problem called underfitting. An underfit model is too simple to capture the genuine patterns in the data. It performs poorly on both training data and new data. An underfit model has high bias, meaning it makes systematic errors, and low variance, meaning its predictions are consistent but consistently wrong.
The goal in machine learning is to find the sweet spot between underfitting and overfitting, a model that is complex enough to learn the genuine patterns but not so complex that it memorizes noise. This balance is called the bias-variance tradeoff and is one of the central concepts in all of machine learning. According to Aya Data, getting this balance right is one of the most critical skills in machine learning practice.
Real-World Consequences of Overfitting
Overfitting is not just a theoretical concern. It has caused real failures in deployed AI systems.
A medical diagnosis model trained on patient data from one hospital may overfit to the specific characteristics of that patient population and perform poorly when deployed at a different hospital with different demographics. A fraud detection model trained on historical fraud patterns may fail to catch new types of fraud it was not trained on. A hiring algorithm overfit to historical data may perpetuate past biases by treating the specific characteristics of previously hired employees as requirements rather than learning what genuinely predicts job performance.
These real-world failures are why understanding and preventing overfitting is so important, particularly in high-stakes applications. You can read more about the broader risks of AI systems in our article on .
Key Takeaways
- Overfitting occurs when a machine learning model memorizes training data rather than learning general patterns, causing it to perform well on training data but poorly on new data.
- The main causes are too little data, a model that is too complex, training for too long, noisy data, and too many features relative to examples.
- The clearest signal of overfitting is a large gap between training accuracy and test accuracy.
- Prevention techniques include collecting more data, using simpler models, applying regularization, using dropout in neural networks, early stopping, cross-validation, data augmentation, and feature selection.
- The bias-variance tradeoff describes the balance between underfitting and overfitting, and finding that balance is one of the most critical skills in machine learning.
- Approximately 85 percent of machine learning projects fail, with poor data quality and overfitting among the leading causes.
Conclusion
Overfitting is one of the most fundamental challenges in machine learning, and understanding it separates people who use AI tools thoughtfully from those who trust impressive-looking numbers without question. A model that scores 99 percent accuracy on its training data is not necessarily a good model. What matters is how it performs on data it has never seen, because that is where real-world value is created or destroyed.
The techniques covered in this article, from regularization and dropout to early stopping and data augmentation, give you a practical toolkit for building models that genuinely generalise. As a next step, explore our guide on to understand how overfitting fits into the broader landscape of how AI systems are built and evaluated.
Sources
- Google Machine Learning Crash Course: Overfitting
- Lenovo: Understanding Overfitting in Machine Learning
- Number Analytics: Mastering Overfitting in Machine Learning
- Aya Data: Complete Guide to Overfitting and Underfitting
- MindInventory: Machine Learning Statistics 2025
Manish Prakash Dubey is an AI educator and technology writer based in India. He founded WiseAIWorld to make artificial intelligence simple and practical for students, professionals, and beginners. His work focuses on AI basics, machine learning, deep learning, NLP, computer vision, and real-world AI tools.